
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- kaggle 프로젝트
- 서비스분석기법
- 데이터직무
- 일하면서성장하고있습니다
- 파이썬기초
- 직무전환
- Python
- 파이썬
- 데이터엔지니어링
- 데이터분석기법
- 데이터엔지니어링시작하기
- 데이터리안웨비나
- 데이터리안
- Growth_Hacking
- ridge 회귀
- 2026목표
- 2026목표세우기
- 비전공자데이터분석가
- 데이터리안월간웨비나
- 데이터분석가
- 데이터분석
- 데이터 엔지니어
- 파이썬오류
- CareerPivot
- 판다스
- ml 실전 프로젝트
- 데이터사이언티스트
- 데이터엔지니어
- 데이터엔지니어링배우기
- 데이터 분석가
- Today
- Total
데이터 분석가 Damla's blog
[Pandas] 판다스 데이터프레임 본문
판다스 데이터프레임은 Dataframe = 2차원표와 Series = 1차원표를 다루는 라이브러리이다!
열이 2개 이상일경우 데이터프레임이라고 칭한다
파이썬에서만 2차원,1차원 표를 다룰 수 있는 것은 아니고 Numpy에서도 다룰 수 있다.
행 = index
열 = colums
하나의 데이터가 있고 그 데이터가 무엇이 있는지 알려주는 것이 Label이다.
넘파이는 1차원 왜 고차원도 다룰 수 있음.
그런데 판다스가 필요한 이유?
라벨을 가지고 있기 때문 -> 라벨이 있어서 더 빠르게 정보를 찾고 계산을 할 수 있다.
딕셔너리 구조가 더 편할때가 있고 키값을 이용할 수 있어서 데이터프레임형식의 라이브러리를 사용하는 것!
데이터 살펴보는 명령어 또는 함수
df1 = 데이터프레임 출력
S1 = 첫번째 열을 시리즈 형식으로 출력
df1.sum() = 세로의 합
df1.mean() = 세로의 평균
df1.values = 가운데에 있는 값만 출력 (함수가 아니라서 괄호를 넣지 않음) = 넘파이의 array
df1.indes = 열의 label을 출력
df1.columns
df1.values > 3 = 넘파이 형식의 출력 값
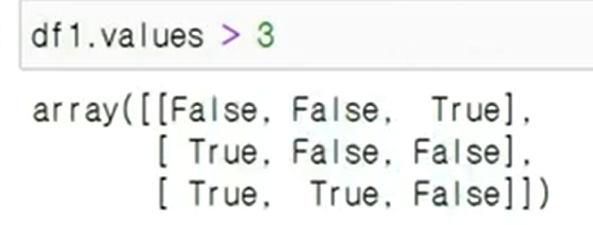
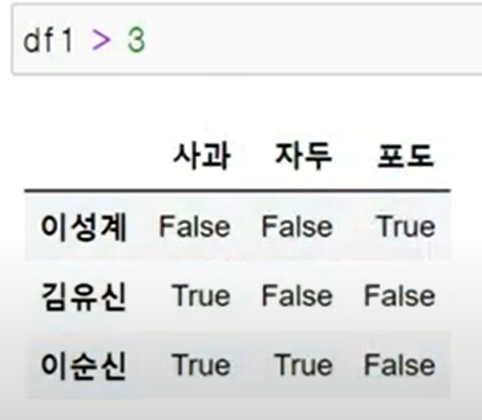
df1 > 3
s1 > 3

bool ; True, False로 구성된 자료형
Tip! 함수가 아니면 빈괄호를 넣지 않아도된다.
데이터 프레임 만드는 방법
1. (초보) 만들어진 데이터프레임 불러오기
pd.read_excel("E00example.xlsx").set_index("이름")
-> 엑셀내에 저장된 데이터프레임을 불러오고. 첫번째 열의 index를 설정하는 함수
2. (중급) 데이터프레임 만들기
pd.DataFrame([[3.2.5]. [10.0,2], [2,8,5]]), index = ["사과", "배', "딸기"], columns=["경남", "전남", "충청"]))
pd.Series([3,10,6], index = ["사과", "배', "딸기"])
출처_ 엑셀투 파이썬
'파이썬(Python) > Basic & Data analyze' 카테고리의 다른 글
| [파이썬]내가 가진 파일의 정보 확인용 코드 .info, .dtypes (0) | 2023.03.06 |
|---|---|
| [파이썬] sort_value (0) | 2023.01.01 |
| [파이썬] 판다스 apply, groupby 코드 설명 (0) | 2022.12.28 |
| [파이썬] 인덱싱과 슬라이싱 (0) | 2022.12.11 |
| [파이썬] Pandas 데이터프레임(Data Frame)이란? (0) | 2022.12.11 |


